The Hive system is a framework to build and connect extremely flexible, reusable Python components. The hive system can be used for visual programming, large 3D applications, game logic, and scientific protocols
Hive is a nodal-logic system designed to work with Python and support visual programming.
Long-term, I intend to add a SCA - like - node implementation for the logic bricks, and an exporter (to HIVE).
Ideally, this would also be compatible with Panda3D.
Like I said, it should be possible (though, not currently a high priority) to write a logic bricks to HIVE exporter.
“Workers” typically represented small operations, though now we eliminated the notion of workers and just have a two-layer system: Bees and Hives. Bees are the basic parts of a Hive - storing data and pushing it along, essentially defining and implementing connectivity. Hives can put these together (and even treat a Hive as a bee) to make more complex logic.
Today:
The UI can now edit args, meta args and build class parameters, so it’s on the way to being pretty functional. Most of that was done today, so there are a few places where I want to ensure I’m being efficient, and safe with data type usage.
An explanation, until the documentation is released:
Hives are effectively “nodes” in the conventional manner. They have inputs and outputs, and can connect to other hives. The Hive itself can be thought of as the node “box”. Without the IO pins, the name, and the values, it’s not very useful.
We can add IO pins to the hive using special code objects call “bees”. Bees are the building blocks of a Hive.
IO Pins are special types of Bees; Antennae and Outputs. These do nothing more than expose the other, hidden bees inside the Hive to the outside world. The reason that some bees are hidden is to avoid making the user interface too complex, and prevent users from using the wrong parts of the node.
Hives (nodes) can be nested within each other, to add more complex behaviour in a single “bee”. This is useful for re-using code, and behaves like Node groups.
Bees can connect with certain other types of bees, according to special rules. If a data type is provided, and it matches, and both bees have the same connection mode (“push” / “pull”) then it is a valid connection. Data types are optionally provided to make the node system “safer”.
“Push” connections are triggered from the output bee, and force the input bee to receive a value. “Pull” connections are triggered by the input bee, and force the output bee to output a value. Trigger connections are a special type of “push” connection that doesn’t send any data.
Most of the time, logic hives should rely on a pull-based system, whilst events (like collision sensors) should trigger an output (push). These can be connected using specific Hives to avoid wasting processing time.
Hive GUI outputs a Hivemap format which can be read by a special function to produce a functional class. In terms of the code-implementation of Hive, it’s divided into three different types of Hive:
Hive. A basic hive which can define Antennae and Outputs, and can change its starting values depending on the arguments used to create it
Meta Hive. A special hive which does the same as [1] but also allows the Hive in [1] to choose how many inputs and outputs to create depending upon the arguments used to construct the hive. When you call the Hive class (MyHive(…)) it returns a special class which remembers those arguments and produces a unique Hive for each combination it receives. This means you can have a Hive that has a variable number of inputs, like so: my_hive = MyHive(inputs=10)(), where the second call instantiates the Hive.
Dyna Hive. A special form of [2], which does everything identically, but only requires a single call. (my_hive = MyHive(inputs=10))
This distinction is only useful if you are writing hives in code. To write a hive, you need two minimum parts:
Builder function: defines the bees within the hive and connects them together. Imagine a robot assembling logic gates together in a factory.
Class factory: Defines the class for the hive by providing the builder function and a name.
Python classes can also be bound to a Hive class to implement existing code without converting it entirely to a nodal logic system itself. This involves a “bind class”.
The builder has two special objects to use in order to define the interface for a hive node; i and ex.
These “wrappers” are basically containers which have specific behaviour when the hive is later built and run. The ex wrapper is the “outside” of the hive (where antennae and outputs go), whilst the i wrapper is the inside of the hive that the GUI won’t be able to see.
There is also an “args” wrapper, which is used to access arguments passed to the Hive. Metahives / Dynahives have another args wrapper called “meta_args” which receives the initial arguments to build the metahive primitive.
The construction process of a Hive is quite important:
A hive class is defined using (at least) the two “parts” mentioned above.
The first time the hive class is instantiated, a HiveObject class is created. This is where all the connectivity and bees are stored. We don’t store these on the Hive class for two reasons: 1, they can change depending on the arguments for meta/dynahives, and 2. hives can be extended like subclassing in pure-Python, so we want to avoid confusing state between subclasses.
When a HiveObject class is created, the builder function is run in “build mode”. This means that the bees it creates are “build” bees, which aren’t the same as the bees used at runtime.
For meta/dynahives a unique HiveObject class is created for each combination of the meta_args provided in the instantiation. This is memoized, meaning it only does the hard work once for these particular values.
A HiveObject instance (not class) is like a “bee” compatible Hive. It can be connected to other bees, and exists inside other hives during build time. When you instantiate a normal Hive class, you get a HiveObject instance during build mode, or a RuntimeHive instance (something else) at runtime.
At the same time as building occurs, the RuntimeHive class is created. It’s populated with runtime bees are runtime, inside its init call.
There’s more to Hive than this small list of points. Accessing other Hives bees during build mode is facilitated using a special “ResolveBee”, functions can be exposed using plugins/sockes etc… But this is the coding basics.
Of course, the manual will be much more concise, and supported with code blocks.
Here’s a dynahive example:
The meta_args parameter is resolved to an actual value when build_variable is invoked.
The args parameter (start_value) doesn’t have a value at build time, because it’s defined before the Hive has been instantiated. The value of this parameter is resolved later on, by the bees that use it.
Not by default. Threading’s pretty difficult to do generically for games, because it’s useful only in specific scenarios. In Python, it’s only useful for blocking routines that wait on something besides calculation, such as IO or intervals (I.E not very useful for speeding up BGE game logic).
Processes are the way to make use of other cores, but again, they’re niche.
I build the list when objects assemble (they add themselves to the list)
and they are popped when they are out of health (and unparent them then) or when they are dissassembled
(There is no code in the part that runs ever frame)
Well, I can’t wait to try hive once it’s finished,
thanks for all your efforts, and thanks for the help.
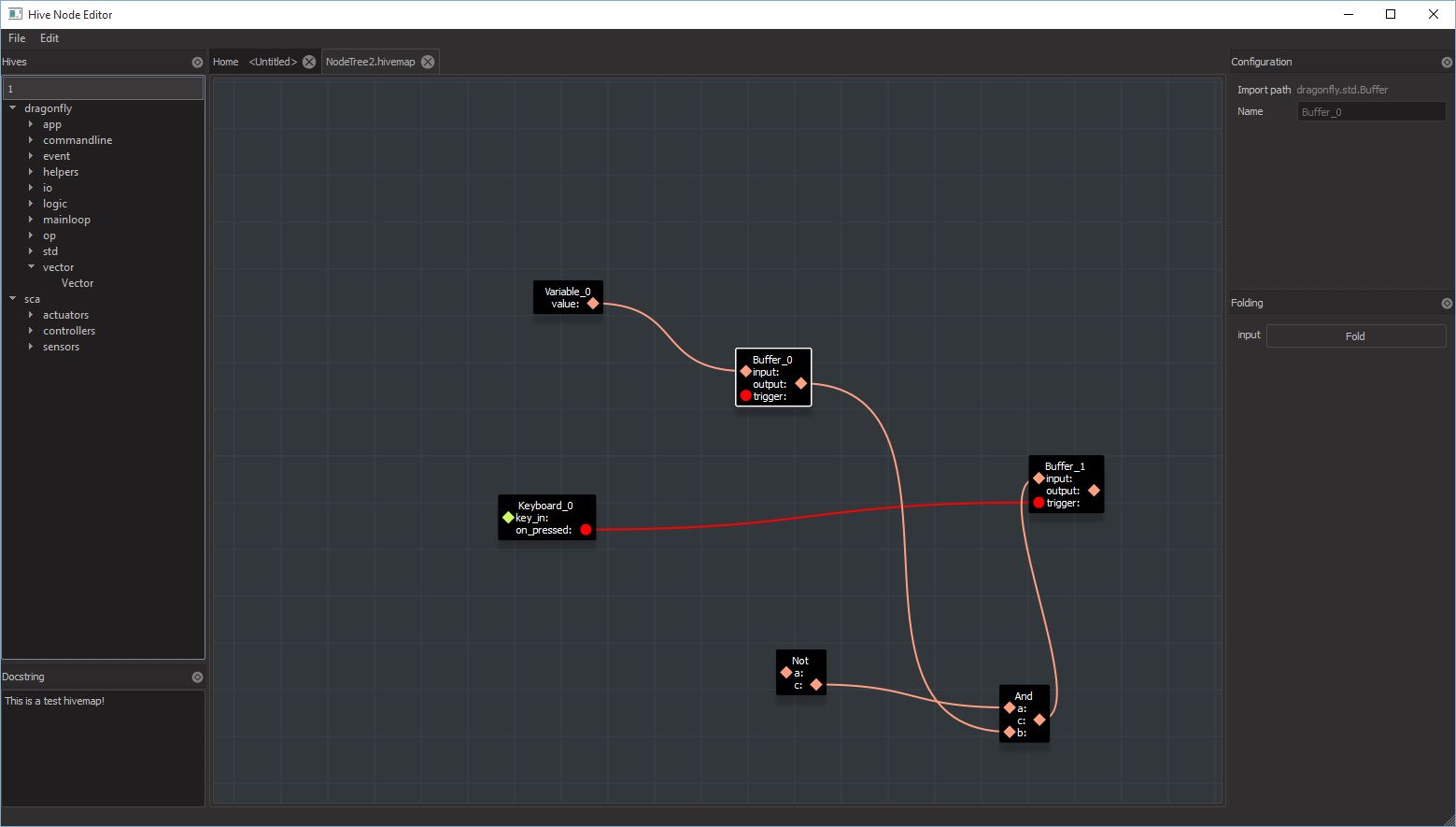
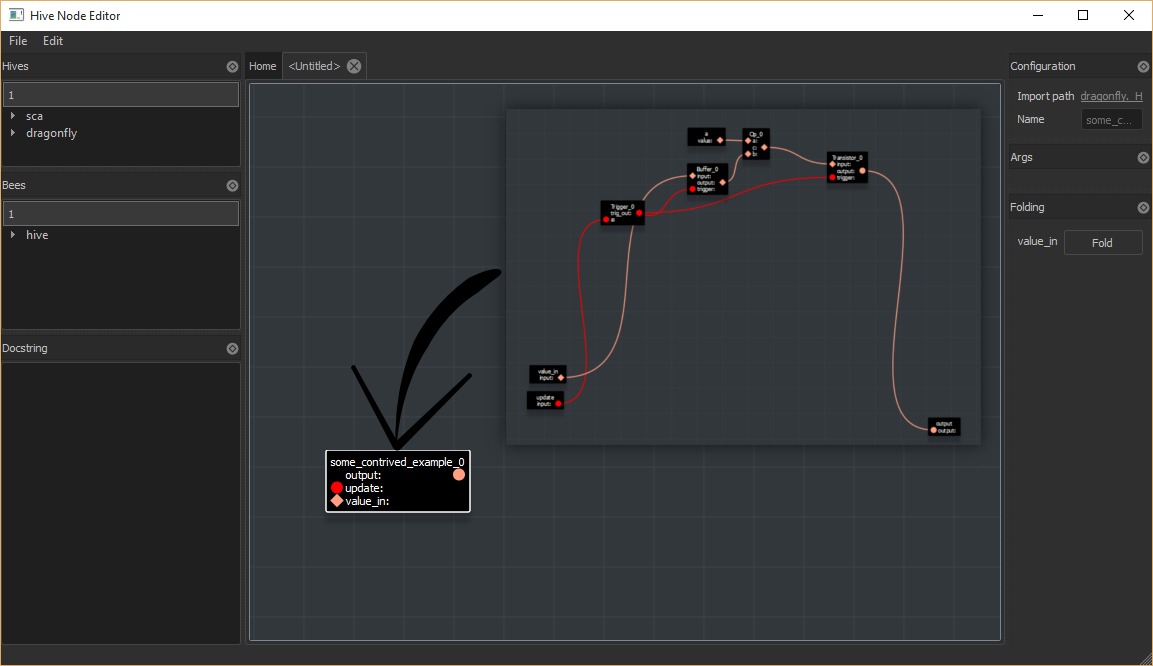
The hivemap in the top right was exported, and a hacky (for now, till the notion of projects is introduced) importer was run. The node in the bottom left was the result. It only has three IO pins even though there are far more in the hivemap. Why?
Well, the bees used in the hive editor are antenna, output, entry and hook. These bees are solely responsible for exposing the hive interface to the outside world. This keeps things simple, and clean, as well as explicit for the node being created. You can see three of those bees in the bottom of the hivemap nodes (top right image)
I’m really enjoy this idea. The lay out from the screen shots look “simple and user friendly”. The graphics of the screen look very complementary. (i always have a soft spot for dark layouts XD) And the idea of you controlling what you see some sort of “minimizing” is very creative. I would use this…if i could learn
So, Hivemaps are now exportable again, and instead of assembling hives directly, a Python definition is built first. This allows power users to optimise startup times by reducing the workload for hive (having to read the Hivemap and do all of the definition logic).
It also means you can learn to use Hive inside of Python, by studying hivemaps.
I added support to intercept triggers inside the GUI. Previously triggers were implemented using hive.connect, which works(!) but doesn’t allow pretriggering.
Pre-triggering is used to trigger other nodes before a particular node is updated - e.g pulling in other numbers before adding them together. Pre-triggers can be connected to using bees only. In Hive, it’s possible to connect to pretriggers from Hive instances, from antennae (input pins) or outputs. However, that’s not easy to express inside a GUI, and also probably allows users to write “bad” hives. It’s better to add this restriction. If a user needs to attach to a pretrigger, they should either add more logic to intercept the trigger that leads to that pretrigger, or mention it to the author of the Hive, who should expose a better interface.
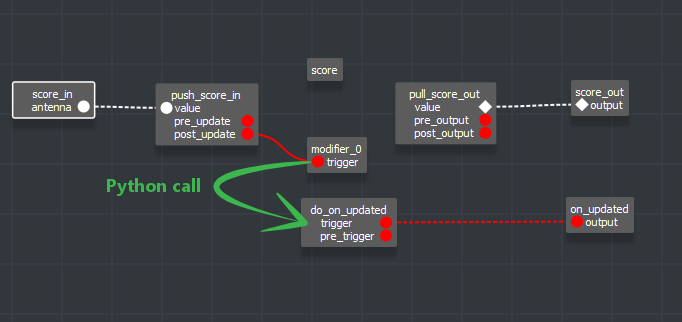
For reference, you can see how the hive.trigger (in Connectivity) will trigger the modifier code when push_score_in is triggered.
Push/Pull/In/Out bees will emit two triggers, first a pretrigger BEFORE they push their value to the attribute (/ function they call if using hive code, not GUI) and then a trigger AFTER the value is updated. Hence, once push_score_in updates the value of score, it will trigger then modifier
Awhile back someone made a point against the naming scheme. It’s just these insect terms aren’t really used in game development. Someone looks for nodes and they’re gonna find of stuff about bees and fluffy bunnies.
Either way it’s awesome that you’re doing this. I guess we can’t be too picky.
I felt similarly when I started using Hive1. Actually, in hindsight, the naming convention did make sense, but that wasn’t immediately obvious to new users. We’ve arguably solved that issue with Hive2, because HIVE is essentially a “product name” like Blueprints, and the difference between hives and bees is that they are different types of node. There’s no perfect single word that can state:
Small-scale building blocks which can be grouped together to form a Hive. Node doesn’t really cut it, because those Hives can also be used as nodes and so on.
Perhaps antenna isn’t immediately obvious. One of the small reasons I think it is important to keep the name is because input (the alternative) is a Python builtin!
Maybe I should add a bunny extension… that shall be the name for metahives!
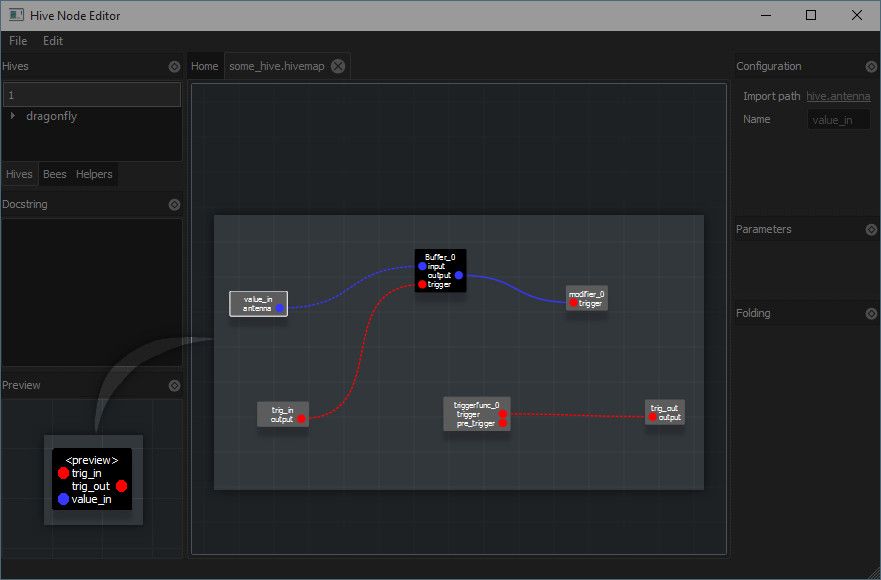
Added ability to preview builder code for current hivemap.
On the immediate TODO list is thinking about how to manage hivemaps for a project (where typically there might be several hives being used for different object types etc).
After that, adding preliminary bindings for BGE will be important. These will require a couple of bigger features inside HIVE to enable this.
I’m probably going to defer the work on the Blender editor until a later point. PyNodes is very restricted in what it can do, meaning it’s very difficult to develop a GUI for Blender (at least, one that can compete with the Qt version, or even come close).
Support for HIVE projects - editing hivemaps from a directory, which can be edited from within the editors that use them. Hivemaps can be imported using the Python import mechanism, in order to support this. A number of bugs (internal and UI) have been fixed.
Primitive runtime-binding is supported, meaning that Hives can be added at runtime with static connection matching! This needs to be expanded before making use in the standard library.
The Standard Library (dragonfly) has been slowly developed, adding support for random nodes, vector nodes, events, IO and other features.